A Plain Text Workflow for Academic Writing with Atom
Why Plain Text?
I used to do my academic writing in a combination of Scrivener and Microsoft Word, but when I started a new book-length project last spring, I found I had new needs:
- a robust citation management system that could change citation styles easily
- seamless cross-platform compatibility (as an owner of both PCs and Macs)
- the ability to organize and manage a large, multi-file project in a multi-pane view (a signature strength of Scrivener)
Neither Word nor Scrivener could do all three, and after asking for advice (references and acknowledgements below), I decided to use a new set of tools for working in plain text: Pandoc with Pandoc-Citeproc for document and bibliography conversion, Zotero with BetterBibTex for reference management, and Atom as a text editor for writing in Pandoc’s version of Markdown. Optionally, one can add a LaTeX suite in order to output typeset .pdf files or to incorporate mathematics or other technical information in .tex syntax inside your Markdown files.
Since this post became, judging by my site analytics, my most popular piece of writing, I’m updating it after a little less than a year using it on a daily basis. What follows is a guide for using these tools in a workflow for writing in Markdown with citation management, converting documents with Pandoc, and doing other processing in Atom and on the command line. This guide will work for you if you feel comfortable using or trying the command line. If that’s not you, I very highly recommend Scrivener for organizing your academic writing and research.
I thought this post would be helpful to colleagues who are interested in the portability and openness of plain text (and share some combination of the needs I list above), but who’d like to see what the editor and workflow might look like before committing to a change.
Tools
Atom or Another Programming Editor
I’ll assume here that you can install the software listed above on your system, and we’ll get into Pandoc and Markdown in the drafting section. If you already use vim or Emacs as a word processor, you probably already know you don’t need Atom, which I chose for its ease of use. It replicates Sublime Text’s killer feature, the command palette, which lets you quickly search for any command (find and replace, wrap text, open a new pane) with one shortcut, ctrl-shift-p, or, on Mac, cmd-shift-p. No need memorize commands as with vim or Emacs, and it’s free, extensible, and open source (though it is operated by GitHub, which is now owned by Microsoft). It integrates with GitHub for version control if you’re into that. And like any programming editor, it needs a number of packages for an academic writing (rather than coding) workflow.
In Atom, I’ve installed, through the “install packages” tab in the settings,
- wordcount (a running wordcount in the bottom of the screen),
- language-markdown (for syntax highlighting),
- file-icons (highlights different file types in the file tree on the left),
- date-time (for quickly date-stamping journal entries or notes to self), and
- notes-from-pdf (which deletes the cruft from copying and pasting notes straight from a .pdf into a .md file)
Helpful settings for me, in the Core and Editor tabs of the Settings, include:
- soft wrap (wrapping lines isn’t something programmers automatically want),
- autosave enabled (beautifully, saves every time you click away from a document),
- autocomplete disabled
- Palatino or another attractive font
- additional panes (constructed through “Split” in the command palette), and
- the “remove empty panes” option disabled, which preserves my Scrivener-inspired three document panes across sessions or document swap-outs.
I’ve listed some other plugins folks have pointed out to me at the end of this post.
It looks like this:
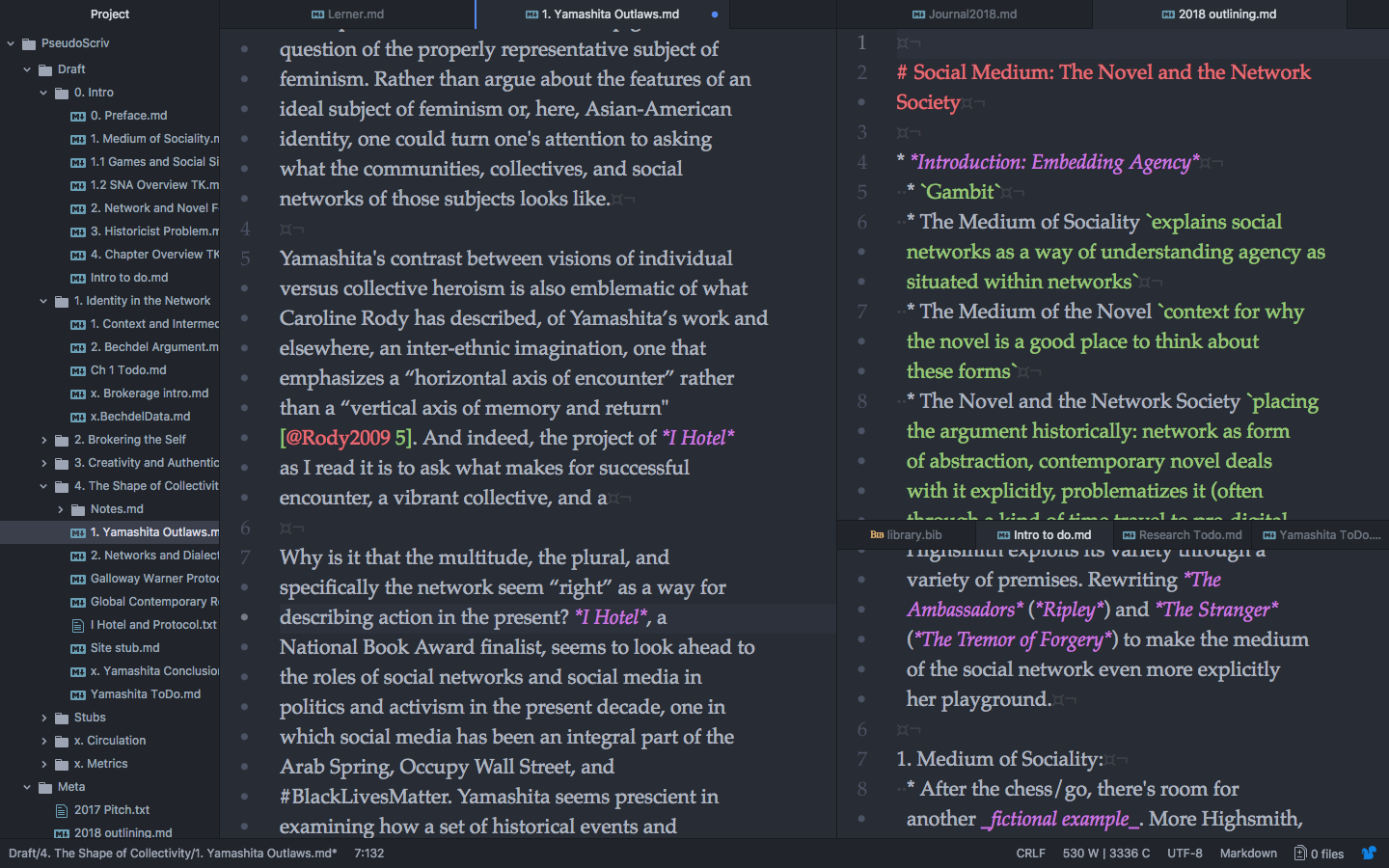
Atom with an open writing project
From left to right: the folder structure for the project, a main document window for draft text, a pane on the upper right for reference (notes on sources or outline notes), and one on the lower right for to-do lists, project-wide searches, or double-checking the bibliography file. All this can be customized however one likes (from arrangement to color scheme to snippets), which is a big advantage of using a programming editor instead of a word processing program. Atom makes it particularly easy to work with the file tree from the keyboard, but I’d be shocked if one couldn’t arrive just as quickly at the setup of one’s dreams in Sublime, vim, emacs, or one of many other editors. It was surprisingly easy to to incorporate all the features I had used in Scrivener, and then some.
Zotero and Better BibTex for Zotero
You can use any citation manager that lets you export to .bib files, but I like Zotero with Better BibTeX for Zotero extension. I simplified the default citation key assignment to be [auth][year] (in the Better BibTeX Preferences tab), and it automatically adds letters to the end of the keys of the fiercely productive or very commonly surnamed. Better BibTeX for Zotero also includes an option for automatic export, so the library.bib file stays updated in the writing project folder, and Zotero’s library also syncs via the cloud. Zotero’s extension for Chrome is also in my experience the best at grabbing correct and complete bibliography entries from publisher webpages, journal pages, library search pages, and elsewhere.
All this means I can cite a reference in my text with the author name, year, and page number in the Markdown format, like this: [@Goffman1959, 112]. I usually open Zotero or know my author and year, but there are also auto-lookup packages for Atom, listed at the bottom of the post.
Drafting
Markdown
I write in the main pane, using the Markdown syntax, which is like a simplified HTML that uses punctuation marks and spacing to denote formatting. It’s quite intuitive: surrounding a word or phrase with asterisks puts it in italics, headers are lines that begin with a number of #, followed by a space, and links, images, lists, and more can be added. (More in this Markdown Cheatsheet). They’re all plain text files, which makes them extremely flexible and portable. I’ll show an example of the syntax below in a moment.
Footnotes
Footnotes are included in the version of Markdown that Pandoc translates, and they’re quite flexible. There are two kinds, and they both use a caret and brackets: an ^[Inline footnote] can come in the middle of a paragraph, while a [^Labeled] footnote refers to a longer footnote whose text is in its own paragraph(s). It’s all numbered automatically when you convert your document. Additional options for footnotes are in Pandoc’s footnote documentation.
Citation
This part is both the most powerful and the most complicated aspect of the workflow. First, you gather sources in a citation manager and sync it to a .bib file. In Markdown generally, you get your unique citation key from your reference manager, and the Markdown syntax is, [@Warner2013, 55]. It’s like parenthetical documentation here, then it gets styled appropriately later.
Markdown’s citation format allows you to add words such as “see” or page numbers or ranges inside the brackets, include a bunch of citations inside a reference footnote, or suppress an author name mentioned in the sentence (using -@) as appropriate. See Pandoc Citation Documentation for more.
Markdown Example
# Sample Article Title
A footnote can be written as part of the paragraph. ^[This is my inline footnote] And my paragraph continues.
Long footnotes can can use a unique label for digressions about *Aesthetic Theory*.[^Adornonote]
Citations just use the key and page number [@Warner2013, 55]. If you're doing a footnote citation style, it mixes fine with inline and labeled footnotes.
<!--HTML-style comments work, too, for notes to self, using cmd-'/' -->
[^Adornonote]: In [-@Adorno1970], Theodor Adorno describes
Atom takes this, adds word wrap, and syntax highlighting to text that’s in a special format.
Processing:
Assuming I’ve got my document, fulldraft.md, ready to share or proof on paper, I’m ready to put it in Word or .pdf format using Pandoc. First, I’ll add metadata (in the similar-to-Markdown YAML format) to the beginning:
---
title: 'Test Markdown Document'
author: Scott Selisker
bibliography: library.bib
csl: chicago-note-bibliography-with-ibid.csl
---
There are many fields one can populate here, such as the article abstract or even the whole .bib file, and Pandoc will read them and fed them into the final document (see Pandoc YAML metadata documentation.) The last two lines here tell Pandoc to use my citation manager’s file library.bib as the bibliography, and the BibTex style sheet chicago-note-bibliography-with-ibid.csl to define the citation style. One downloads style sheets from a repository linked through CitationStyles.org. Literature scholars can, for instance, find different MLA editions, different variants and editions of Chicago, and a few journals’ house citation styles. One could in theory edit one of these .csl files to conform to some aspect of a publisher’s or journal’s house style, or else pipe the file with a close-enough match into a .docx or .tex file and fine-tune the results.
Next, I’m ready to have Pandoc do its jobs—delightfully, it’s converting from plain text to a format of my choosing (.pdf, .docx, .html, .tex, .odt, etc etc), turning Markdown into styling in that file, and turning my citation tags into fully formatted references with the bibliography specified above (using "--citeproc" in the most recent version of pandoc). All in this command:
pandoc -s -o seliskerdraft.pdf --citeproc
fulldraft.md
Translation: Pandoc, make a (-s)tandalone (-o)utput file called seliskerchapter.pdf, using the pandoc-citeproc filter (the package for bibliography functionality) and do it with the input file fulldraft.md. And here it is:

Two other examples: The first, pandoc -s -o seliskerdraft.docx --citeproc
fulldraft.md makes me a .docx file instead.

Now, to really live the dream, let’s put it in a different citation style in one command. We can override the citation style sheet (that YAML line from above) by specifying it on the command line, to spit out this article in MLA style rather than Chicago:
pandoc -s -o seliskerdraft.pdf --citeproc --csl=modern-language-association-7th-edition-with-url.csl
fulldraft.md

I hope folks find this useful. Happy writing.
More Info
Importing from Word
This is the worst part, but it’s no worse than changing citation styles. I recently repeated it after back-and-forths with a journal took place in Word with extensive changes. This is also where you’ll have to start if you’re bringing in work already completed in Word or Scrivener into Atom. Happily, Pandoc can convert your file from Word, though you do need to set a flag set to remove extra carriage returns within paragraphs: pandoc -s -o chaptersection.md ArticleinWord.docx --wrap=none
As you might expect, Markdown-style citations don’t transfer back from .docx to .md—footnotes come back fine, but labeled by number, and parenthetical citations are just text. Find and replace makes relatively quick work of parenthetical citations. If you can leave footnotes in place, you can just give the imported section unique footnote tags with find and replace within the text editor (\[\^ -> [^ChapterName labels them ChapterName1, ChapterName2, etc.). The citation tags you have to insert, the [@Goffman1959, 112]’s, are at least shorter than the full citations in a different style.
My File Structure and Other Commands
This will likely come down to your preference, but I’ll describe what I do. To replicate the Scrivener sidebar experience with the file tree, I decided to put chapter drafts in their own folders, and different subsections of chapters in documents named with numbers. This lets me put short to-do lists or other documents in the folder, as in the screenshot above. (To-do lists work great here—ctrl-/ comments out, and greys out, the current line to mark an item complete.)
I can then compile a draft of a particular chapter or, below, the whole book (all subfolders, all .md files whose name starts with a number) from the command line in the main folder of my project, using:
cat Draft/*/[0-9]*.md > bookdraft2019-01-01.md
I then just have to add the right YAML metadata at the beginning of that (I set up an Atom code snippet but there are other ways) before using pandoc as above. I’ll also note that wc on the command line gives a handy list of the individual and total word count within that folder structure: wc -w Draft/*/[0-9]*.md.
Because these routine things vary from person to person, I just keep a .txt file with common commands in my draft folder. Some writers prefer to write a simple bash script to do these things, or you can use Raphael Kabo’s simple Mac app DocDown to use a drag-and-drop interface for the draft, citation stylesheet (.csl), and bibliography (.bib) files.
Additional Resources
A few links I found useful in figuring this out: a big source of inspiration was Dennis Tenen and Grant Wythoff’s Sustainable Authorship in Plain Text Using Pandoc and Markdown. For those who want to do version control or work seriously with data and visualizations in a setup like this, I also recommend Kieran Healy’s Plain Person’s guide to Plain Text Social Science, and Moacir de Sa Pereira’s guides to Atom for his JavaScripting English Major course: The Atom Programming Environment and Atom Help, both of which address version control.
It took me a while to figure out that Markdown formatting questions are all answered in the Pandoc Manual. There are many Markdown flavors, but what’s important is Pandoc’s implementation of Markdown, which includes many features for academic writers.
And, finally, for those starting with citation management, I was delighted to find the reasonably functional text2bib, an online tool that does its level best to convert a copied-and-pasted bibliography into .bib format for easy importing into a reference manager. Its interface lets you double-check them one at a time or download the .bib file and correct it in the reference manager.
Additional Atom Packages
If you work with single long .md files with a lot of headers and subheaders, the “document-outline” package offers, as @HLAgeek notes, a terrific way to navigate a longer single document by its sections.
If you don’t want to remember your bibliography keys for citation, there are Zotero-citations (by the author of Better BibTeX for Zotero), autocomplete-bibtex, and Zotero-picker, each of which uses a different approach to streamlining the lookup process.